
Important: The research described in this article is based on, and may contain some amount of, extremely sensitive data. My intention with this research is to help defenders protect people from malicious actors. As such, I will be unable to share some details or pieces of data in order to protect the data authors. **Do not** request access to the raw data, including email address and PII. These requests will be ignored.
A little bit of background
The modern digital age is a fascinating thing to me. Technology really has come a long way in just a short span of time, and it's now embedded in every part of our lives from the mundane to the critical. Our most personal and sensitive pieces of information live in this digital realm and are constantly at risk from threat actors around the world. And that's one of the amazing things; the threats aren't just obvious or local anymore, they are anything and everywhere. It's remarkable that despite the level of critical sensitivity of our data, the password is still our most prolific choice for authorizing sensitive data. It's true that we do have alternative authentication mechanisms now, like biometrics, one-time tokens, and a variety of others, but passwords remain the cardinal mechanism which most people will interact with. So one would assume that it would be pretty important for defenders to analyze passwords, their mechanisms, and their processes in order to help better protect people from the various threats in the world. Unfortunately, I have seen this as one of the area defenders are lagging behind in. There is research constantly being done, but not as much as there needs to be, not always for the benefit of people as a whole, and not often publicly.
Working as an information security professional, I've had the opportunity to work with some wonderful people and become exposed to some very interesting information. One of the more interesting is a data set I have been graciously permitted to utilize in my research, which was collected about 2 years ago. I was invited to participate in a post-mortem of a data breach for an online website. The breach itself only lost email addresses and passwords to the attackers, but I was asked to discover the potential scope of the SQLi vulnerabilities in the site. By the end of my analysis, I had a collection of 18.2+ million records of user data that extended far beyond what the attackers realized they could grab. Sexual orientation, birth dates, body type, hair and eye colour, occupation, religion, locations, ethnicity, etc... it was all there. The most sensitive collective data set on people short of including tax IDs and payment info was just sitting in a giant CSV file.
The company was actually pretty remarkable in their response. They notified their customers within 24 hours, performed password resets, made various changes to the infrastructure to protect against further exploitation (to name just a few things). I was pretty impressed, to be honest, because I've seen quite a few notable companies do far worse in the same situation. The sad part is, none of it mattered. The damage to reputation was too great, they lost significant traffic, and ultimately the business was shut down.
In the aftermath, I realized there was still an opportunity to help other data owners secure their data, and I was fortunate that the data owners agreed with me. Malicious actors are spending tremendous time and resources on analysis of private data they have collected from breaches, but now a similar set of data could be analyzed and hopefully provide defenders with additional insight these malicious actors have gained but were previously not publicly available. So just how useful is this metadata to an attacker? Is it possible to correlate a data author's demographics to their cognitive process when creating passwords? Is it possible to extract patterns that could help narrow the scope an actor would use during an attack?
Why is this data important?
I must divulge one last piece of information for this story to make sense. When this company was acquired, it was discovered that the original programmer of the web site created a custom "encryption" algorithm to store the password data. (I intentionally put encryption in quotes, because the implementation acted more as an encoding and I can not qualify it as true encryption.)
Fortunately, the new owners acknowledged this was incredibly poor and launched a project to convert all of the user passwords to bcrypt with a cost of 14 (for those who don't understand, the cost is a value used to exponentially grow the amount of work bcrypt uses to protect data. At the time, 5 was about average and 10 was considered very good.) This turned out to be a project that would last many months to complete. Unfortunately, the original column of encoded passwords was not yet dropped by the time of the breach.
In my post-mortem, It took me approximately two hours to reverse the algorithm using some Perl and chosen cypher texts. Five minutes later, I had fully decrypted all 18.2+ million password records that were available in the data set.
Any other massive data set we have been able to analyze previously has only been able to be represented by the passwords we have been able to crack, and none of those data sets have had a 100% recovery rate. So any other data set can be considered questionably skewed for analysis. But this is a complete representation of data set, giving us a perspective that has been previously unavailable at this scale.
A Note for Web Developers: Don't roll your own crypto. Use industry standards!
The Journey
Unfortunately, due to balancing my time and responsibilities, I was unable to really look at this data until December 2015. Once I did, it was fairly obvious that analysis of the data in CSV form was going to be horribly inefficient. The data was imported into a SQL database, where it could be queried both directly and through the use of a series of custom python scripts.
There were three things I really wanted to study from this data:
- Any patterns found in the data
- The relation of topologies
- The entropy of the passwords
Patterns are fairly straight forward. We can look up specific traits of character sets or compare the plain texts to dictionaries in order to find substrings.
Topologies are also fairly straight-forward. If you are unfamiliar with the concept of password topologies, I invite you to look at the research presented by KoreLogic on their PathWell technology and Password Wear-Leveling. They have dedicated a tremendous effort into this research and it's well worth the attention. At a high level, the topology is the representation of the available keyspace for a selected password through the use of per-position character set designations. These topologies can then easily be represented in a targeted keyspace attack, for example using masks in Hashcat.
To illustrate this, imagine you have the password "Cat13". Your topology would consist of one uppercase character, followed by two lowercase characters, followed by two digits. Or, as a Hashcat mask: ?u?l?l?d?d
As an additional point of interest, I wanted to compare how the popular topologies in this data set looked as opposed with the known topologies of industry standard data sets like Rockyou (available in dictionary form on skull security's site.)
Measuring entropy
Finally we need a way to determine how complex a given password is and how difficult it would be to attack. I decided to use DropBox's zxcvbn library to calculate the effective entropy, as it gives a more realistic and practical interpretation of the difficulty in cracking a password rather than just a purely theoretical and scientific interpretation of the password itself. Although not a complete 1-to-1 comparison, we can reasonably assume that passwords with higher entropy scores are harder to crack than those with lower scores.
Once I generated these values, I graphed them for each demographic. This creates the Entropy Distribution Curve (EDC) for that demographic. Examining a demographic's EDC is an easy and quick way to visualize the effective difficulty of cracking a particular demographic's set of password hashes. With this, we can examine groupings of entropy where authors are likely to create passwords with similar complexity traits.
As an example, here is the EDC for people with athletic body types:

From this graph, you notice that author entropy tends to dipose around 20. Focusing on patterns close to this entropy score will yield a higher percentage of cracks compared to a straight brute force or even topology attack. Ideally, we would want to see entropy which is distributed across the entire spectrum and with as few peaks as possible. EDCs with tighter groupings (especially at the lower end) and more peaks are considered weaker.

Interesting data
After analyzing these patterns, we start to reveal properties which attackers can leverage by crafting only a few targeted rules. For example, a targeted mask attack containing just a handful of topologies comprised of numeric sequences at the end of lowercase characters is likely to retrieve the plain texts for a third of any given mass data set of password hashes. We can also determine that only a few targeted demographics can increase the potential complexity (and possible difficulty for cracking) of a password. Such an example can be seen in the income demographics, where nearly all income levels have low EDCs until you reach individuals earning over $125k annually who then hold a much more diverse EDC.
When I first started this analysis, I was really hoping to discover some sort of correlation between the demographics and various patterns that may pop up with the passwords authors chose to create that could result in some type of game-changing revelation. Unfortunately, the results contained no significant deviations which I could determine to be statistically relevant in proving this. In fact, all I can really tell from this data is that all people (regardless of status, race, occupation, or other varying metrics we have available) share similar cognitive processes and repeat similar patterns. It's not a fact that should really be surprising, but it's one I feel that is often overlooked. In the end, people are just people.
Character sets
The first thing worth noting are the character sets used. Of the 18.2+ million records, about 1000 of them used any kind of unicode. Removing those entries, we have 18290271 records left. Using this data, we can make some immediate observations about the usage of particular character sets.
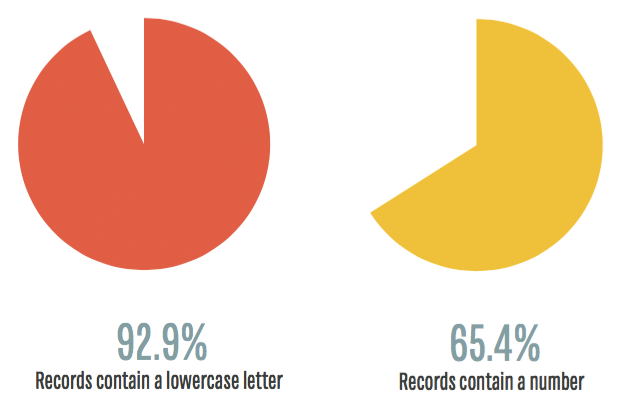
From an attacker's perspective, they can assume any password they are going to attack will contain a lowercase character and immediately obtain targeted keyspace masks that may be used in over 92% of password data sets. That's an incredible aid when cracking passwords. What's further, they can assume that well over half of these passwords will also contain a number.
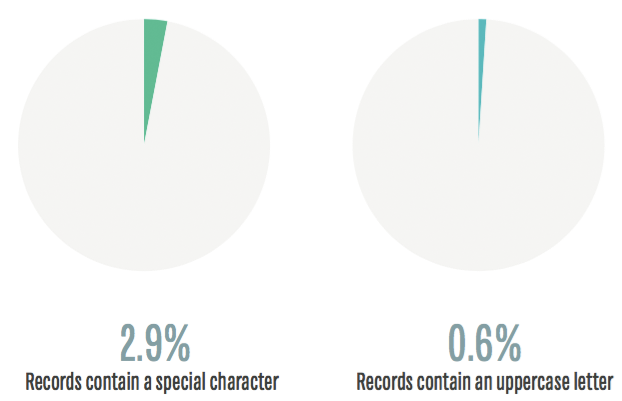
Unfortunately, less than 3% of these passwords are using special characters like @#%!. Even worse, less than 1% of the data set uses uppercase characters at all! So for all of you out there will uppercase characters in your passwords, let me congratulate you for being in the top 1%.
Topologies
None of the popular topologies contained special characters, characters from a unicode character set, or even upper-case characters. The data here seems to mimic other public breaches from commercial websites. The one thing worth noting is the comparison of these topologies against both the Rockyou breach, and the PathWell research performed by KoreLogic. KoreLogic's data came from enterprise environments where strict password policies are often affected and as a result the topologies are a little more diverse. When examining the Rockyou breach and the data in this research, much different and simpler patterns are revealed. As has been said many times before, it appears that when given a choice people will prefer easier patterns over complex patterns.
Most common passwords
Across the different demographics, the list of common passwords looks to be quite similar. Unfortunately, this data isn't very interesting, as it more-or-less emulates the common patterns of a global data set. As an illustration, here are a few of the top 10 passwords for a random sampling of demographics.
Number behaviour
Users seem to prefer numbers at the end of a password (The percentage of passwords using numbers at the end are generally within 10% less of the total percentage of passwords using numbers at all.) However, if a user places a number at the start of their password, there is a high probability that they will add a number at the end as well.

Only between 6% and 12% of any particular demographic used four numbers at the end which also represented a year from 1900-2013. Although significant, it would probably yield more successful results to simply comb through all combinations of four digits that to focus on specific ranges of years.

These patterns are actually quite specific, and can furthermore be seen across all demographics. Unfortunately, this (once again) gives malicious actors an advantage.
Patterns
Looking for patterns was a little interesting, and there were a myriad of ways I tried to do so. The first was to see how many entries contained sub-patterns that were taken straight from the dictionary (I used webster's dictionary for this.) My original attempt at using a python script here was incredibly slow, so I decided to do this in perl instead. Performance was exponentially greater with perl for this workload.
I was able to discover that from the global data set, 35% of entries contained sub-patterns that could be found straight from the dictionary. This is significant because it creates a smaller potential gap between the candidates being fed into the password pool, and the Levenshtein Distance needed to turn a candidate into a successful crack. The deviation across demographics seemed to be statistically insignificant.
I then tried to examine the EDCs. The goal here was to see how much entropy a particular demographic was likely to utilize for their passwords, which might suggest the quality of complexity patterns needed to attack the group's set of password hashes.

Of the religious demographics, authors identifying as Buddhist, Mormon, Hindu, Muslim, and Jewish demographics had EDCs with lower peaks and a wider distribution. The Hindu demographic seems to have the best EDC overall. Authors identifying as Christian, Catholic, and atheist held the poorest EDCs in the religious demographics.

Of the occupational demographics, Architectural Services, Biotechnology, Employment Placement, Internet/E-Commerce, Science, and Politician demographics held the best EDCs (users identifying as Politicians had a significantly improved EDC than any other demographic.)

Finally, the Sales and self-employed demographics held the worst EDCs from any of the occupational demographics.
Final thoughts
There is a lot of work yet to be done. Although there were few specific patterns and processes that were able to be linked to specific demographics, this result is in a way even more damning. A malicious actor can successfully assume the same techniques and patterns for any data set they were to come upon and be successful at revealing a large percentage of passwords.
The real question becomes, how do we protect data owners and the data authors from attacks and abuse of their secrets? Although this is a truly complex issue to solve, I believe it will probably involve some manner of wear-leveling for password use, and security education. Too many people aren't even aware of the dangers they are exposed to, which only serves to increase the complexity of the issue.
Until a better solution is uncovered, I would highly recommend usage of a password manager. Create a single, complex password that you can remember, and let your password manager generate arbitrary random passwords for all of your sites and services. Make them at least 32 characters, and use all character sets, because why not? If you don't have to remember it, it can be as ridiculous as you want it to be (and it should be!)

A parting gift
I will include a download here for the appendix of compiled data I used while writing my research paper (yet to be finished at the time of this writing.) Feel free to take it and analyze it! I would love to see what kinds of defenses we can devise from this information.
Additionally, I thought it would be useful to offer (with permission from the data owners) defenders a dictionary compiled from the password data here. To make this useful and to respect the requests of the data owners, this data will be slightly sanitized in the following ways:
- Unicode entries will be removed from the dictionary (since there are so few of them, they are not very practically useful from a defender's perspective)
- Passwords which directly refer to the data owners will be removed (these entries would be specific to this one website anyway, and are also not useful in a practical manner)
- finally, entries which are known to belong to bots will be removed (these entries do not accurately reflect password authors' behaviours and only skew the results of a dictionary in unfavourable ways)
That said, the rest of the data is provided here to be used in lawful purposes! I hope this helps many of the defenders of the realms out there.
